

design a parking lot python video
Parking spot detection using Mask-RCNN
How to detect a parking spot availability using Mask-RCNN?
![]()

I have recently worked on a project to detect whether the parking spot is available or occupied based on security view camera photos. There are limitations to my work which I will go into more detail further, but once these are resolved this project may be a low-cost solution to optimize parking availability. There's certainly a potential in this project to simplify the process of finding a parking spot in a given area since most of the parking lots have security cameras placed and this way the parking lots won't need any additional equipment being installed.
Let m e elaborate on the resources that I used for this project. There's a Parking Lot dataset available on Kaggle that has enough data points for training a deep learning model and xml files with annotations whether the spot has been occupied or not. You can access the dataset here parking lot dataset. For the model, I used state-of-the-art object detection and segmentation Mask-RCNN model which performs amazingly and can be accessed via this link.
As you can see Mask-RCNN out-of-the-box pre-trained on COCOdataset model does an excellent job at object detection and segmentation. Although in some cases it misclassifies cars for train and truck.

On a side note, I also tried YOLO-v3 which performed identically so I didn't go in further with YOLO model but if you're looking for alternative YOLO is an awesome model for object detection, here's the link.

At first I used Mask-RCNN model to detect the cars on the parking spot, and given the number of spots available calculate the empty slots. We don't need all COCO classes for our model, so I limited the clasess to cars, trucks, and motorcycles. But the pre-trained on COCOdataset model doesn't do an excellent job in detecting small objects even though I tried tweaking the threshold and bounding boxes and those cars that are being misclassified as trains are not detected. Here the bounding boxes are drawn instead of masks that are provided with model's visualize method.

Given the above performance I decided to train the top layer of the COCO model not only to transfer knowledge from the pre-trained model but also to improve the predictions based on our dataset, so that we'll have two classes to predict whether the spot is occupied or empty.
The constraints of this parking lot dataset are such that the photos are taken from two perspectives only which leads to overfitting issues with training the model and do not allow to generalize better. Secondly, the annotations of each parking spot are not complete and thus raise exceptions during training, furthermore not all parking spots available on the photo are annotated which also leads to poorer performance of the model. I'll show you what I mean, the photo below just shows how many parking spots are annotated:

Many xml files didn't have occupied class filled in:
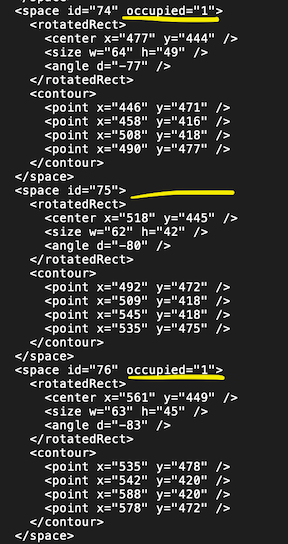
And the number of parking spaces with missing info can rise to around 10–15 spaces. I thought this could be fixed manually, but after running some code:

There are far too many files to be fixed and for purposes of training only the top layer of the model, it's easier to avoid these files. For parsing an xml file I used XML.etree.ElementTree built-in python package. It is worth noting also, that coordinates of the bounding boxes are given at an angle with a center point, so some adjustments to parsing and creating bounding boxes are essential if we want to do it properly.

Since Mask-RCNN uses masks for training the classes, in a similar fashion to Kangaroo Detection article, that can be accessed here, I used bounding boxes to create masks. This article actually helped me a lot in understanding how to use Mask-RCNN model and Machine Learning Mastery in general is a great resource for many machine learning applications. So check it out, if you haven't yet. The main difference is that we going to have 2 classes detected instead of one and thus create masks based on the occupied classification, and also how the bounding boxes are calculated.
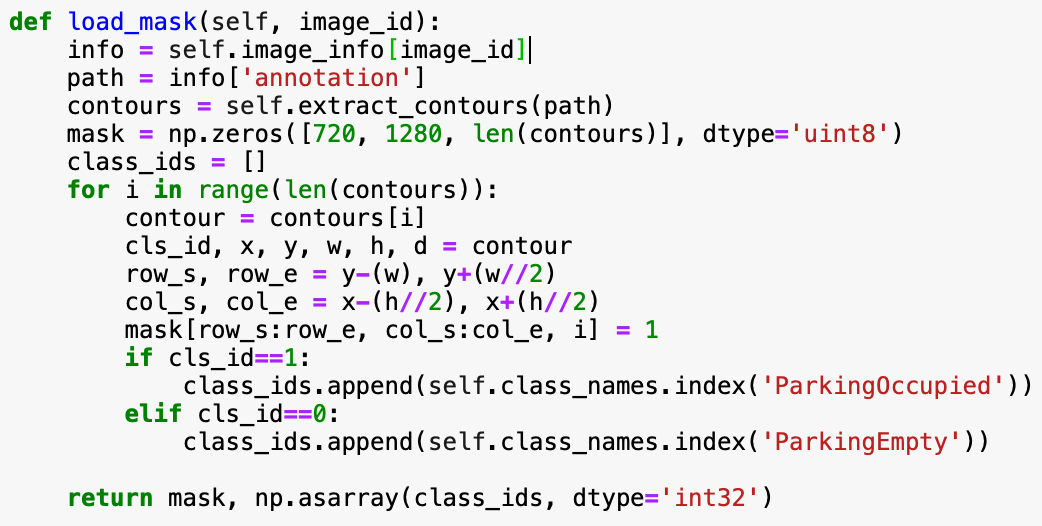
As for the dataset organization, we have to create two directories for train and test data, each containing image folder and matching label folder, where each xml file has the same filename except for an extension. Whilst the rest is practically following the general practices to train top layer of Mask-RCNN. You can check different sample codes on the Matterport GitHub.
We have to create a class ParkingLot that will load the dataset, extract the contours of the bounding boxes by parsing xml annotated files, create the masks based on the extracted contours and we'll need an image reference function that will return the path to annotated xml file.

Then we'll need to specify config class based on the classes that we want the model to be trained on, load the train and test datasets, load the model using the 'training' mode and start training.
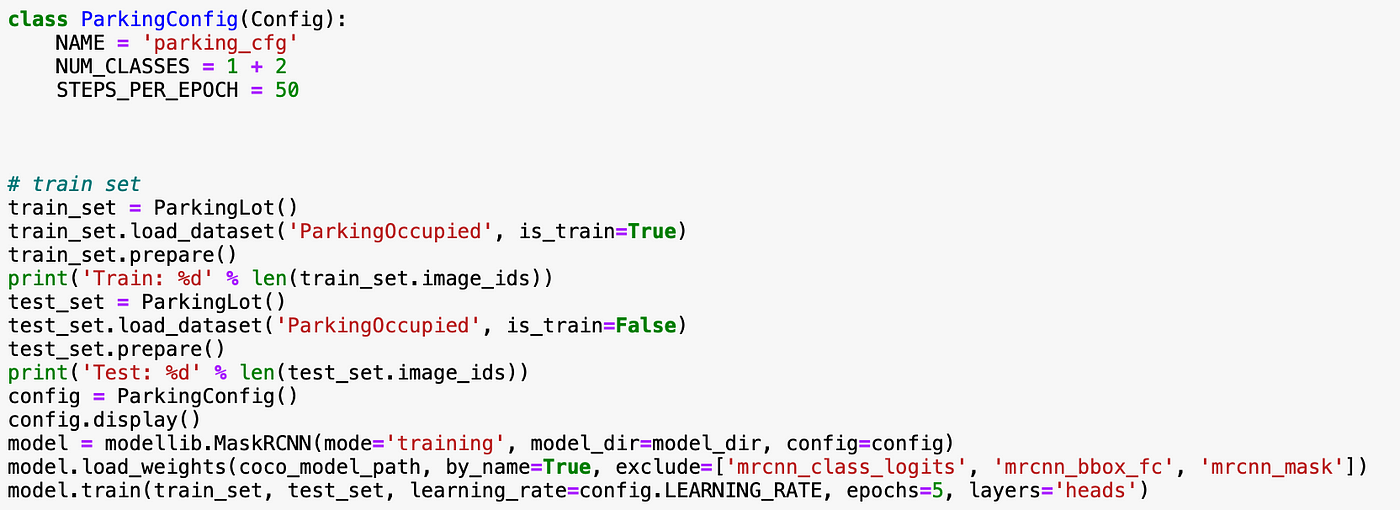
The model will be saved in logs folder after each epoch so that once the training is complete, you can go ahead and load the model to evaluate its performance. The way to do that with Mask-RCNN is to create new Config class that would limit the scope of our predictions
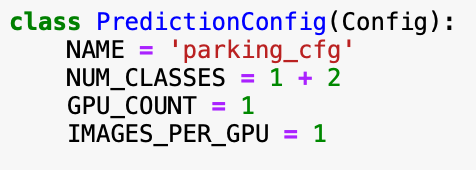
Load the model with the 'inference' mode, load the model from the logs folder:
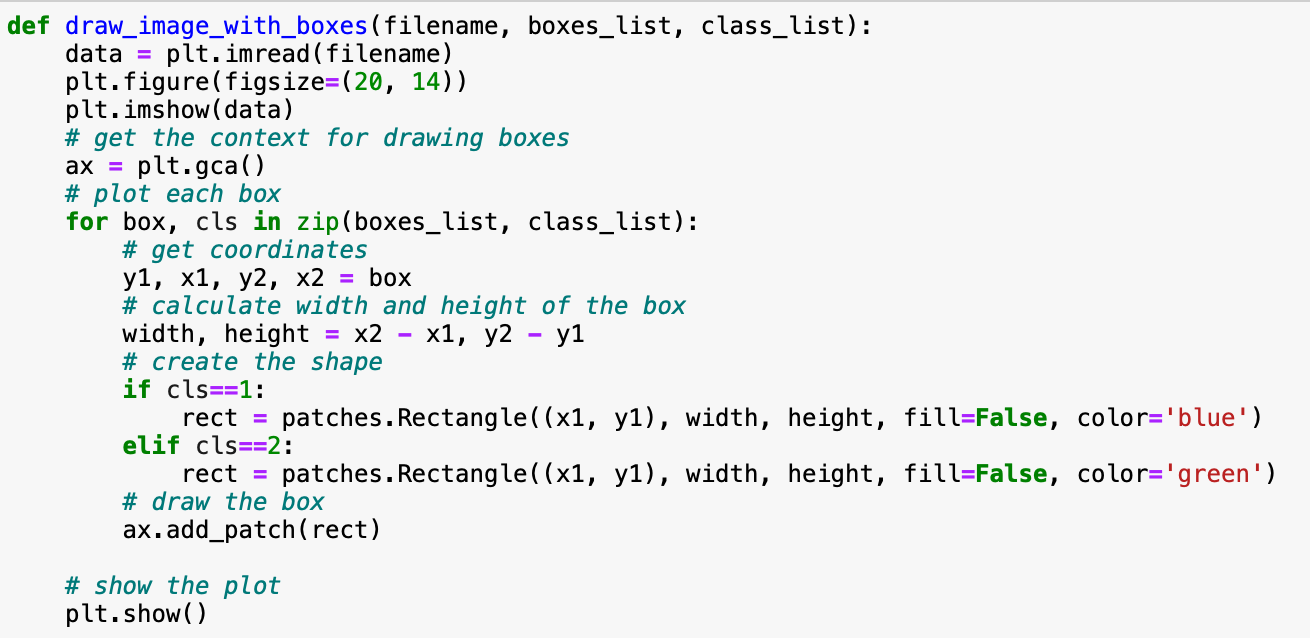
Since the Mask-RCNN visualizes the masks of the detected objects and it's class, we will use this function to draw the bounding boxes:
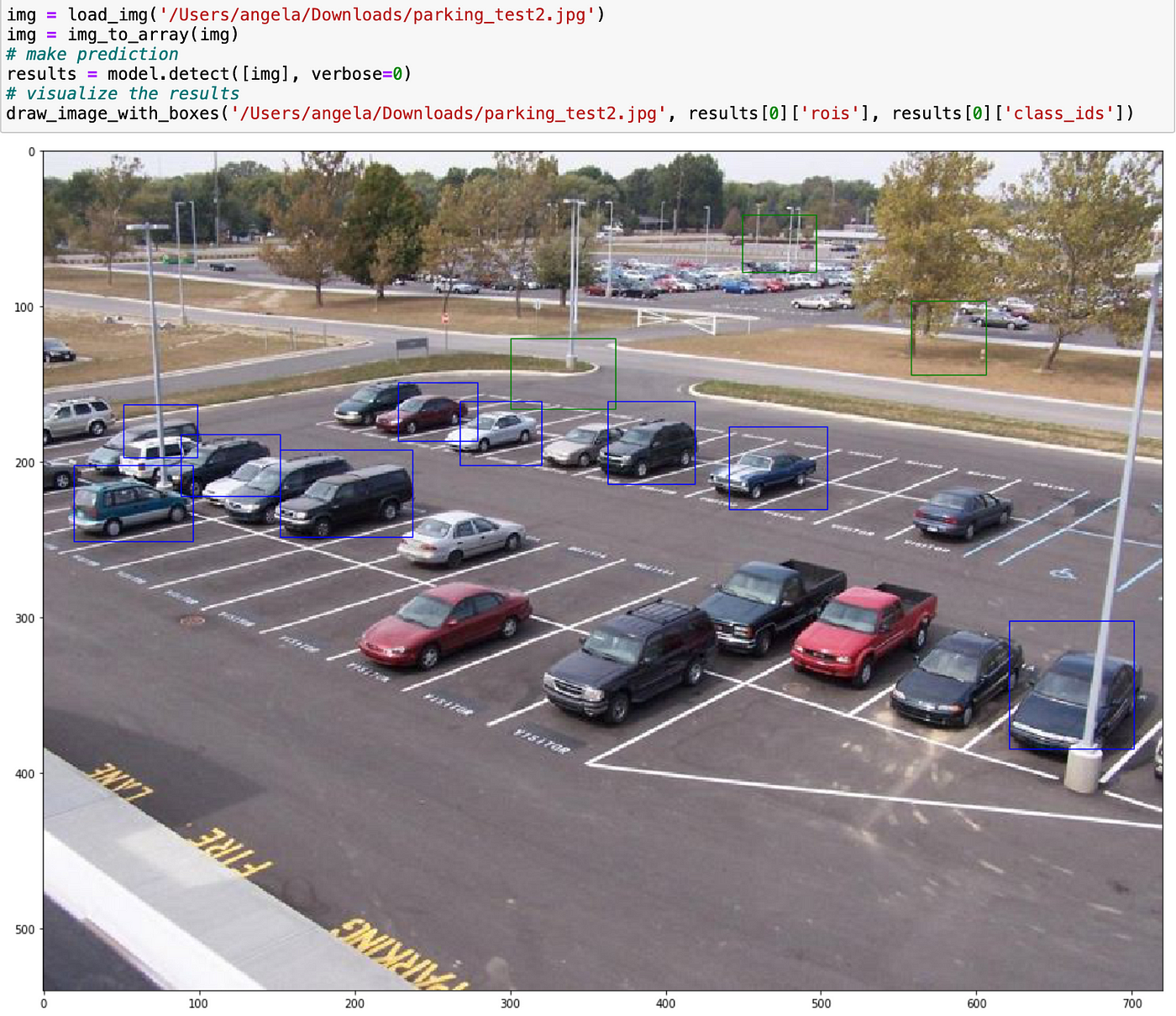
So if we load any random image, detect the available and occupied parking spots, use our function to draw them, this will be the result:

The green boxes are the available parking spots and the blue bounding boxes are the occupied parking spots. It seems that the model performance is pretty good, although it's still not detecting small cars/parking spots. The cars that are parked alongside the pavement were intentionally omitted in the dataset so that the model wouldn't take those cars into account whilst training. This is how the results will look like with Mask-RCNN's visualize method:

Given this results it seems that the model's performance is really good. But in our dataset we have only two angles of the parking lot, and since I was training only top model, I used only a portion of the dataset. So why not look at another photo of the parking lot with a similar camera positioned but not part of this dataset. How good our model is going to perform then?

Wow! This is just bad! It's pretty obvious that the model is overfitted to our Parking Lot dataset, meaning it performs well on the same dataset, I didn't say training since training and testing photos are practically the same photos with different cars positioned in the parking lot and although there's no technically a leakage of test data but in a sense they are the same. Out-of-the-box pre-trained Mask-RCNN would perform much better at detecting vehicles.
Given these conclusions and the limitations that I mentioned earlier what could be the next steps in order to improve the model or move forward? Well, we can train the model from scratch using whole set of data and see how it performs, try tuning detection threshold. I might as well try and do that, maybe that could be a part II of this post? But ideally, more varying dataset is essential with complete annotation is fundamental to create an accurate parking spot detection model. Furthermore, in order to build not only accurate but also robust detection model, I'd say that it is really important to account for cars that are moving and not parked yet, unauthorized parked cars. These maybe further steps to look into in the future.
Thank you for taking your time to read my post!
design a parking lot python video
Source: https://towardsdatascience.com/parking-spot-detection-using-mask-rcnn-cb2db74a0ff5
Posted by: leachcalist.blogspot.com
0 Response to "design a parking lot python video"
Post a Comment